
[하위질의 (SubQuery)] \
: 하나의 쿼리에 다른 쿼리가 포함되는 구조, ( )로처리
1) 단일 행 서브쿼리(단일 행 반환) : > , < , >=, <= , <> (!=)
Main Query
Sub Query -----> 1개결과
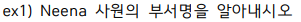
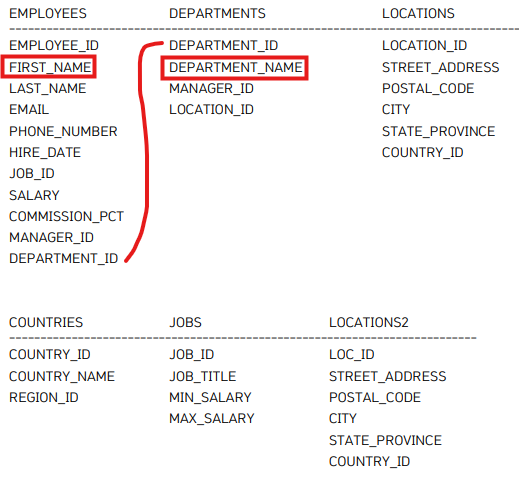
여기서 JOIN을 걸어야할지 Sub Query를 걸어야할지 고민해야한다.
부서코드를 알아낼 수 있는지 본다.
코드넘버가 90번이면 90번인 사람의 이름을 알 수 있게 되는 것이다.
select department_id from employees where first_name='Neena';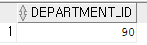
select department_name from departments where department_id=90;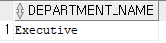
이렇게 따로 쓴 코드를 합쳐야한다.
select department_name
from departments
where department_id = (select department_id from employees where first_name='Neena');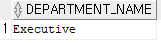
괄호 안에 있는 sql문 먼저 실행하여 부서코드를 알아내고
where문을 실행하여 그 부서코드에 있는 사람의 이름을 출력한다.

먼저 Neena라는 사원이있는 부서를 찾아야하고, 급여를 더 많이 받는 사원을 찾아야한다.
select department_id from employees where first_name = 'Neena';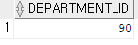
select salary from employees where first_name = 'Neena';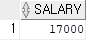
select last_name, department_id, salary
from employees
where department_id = (select department_id from employees where first_name = 'Neena')
and salary > (select salary from employees where first_name = 'Neena');

select min(salary) from employees;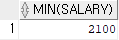
select last_name, salary
from employees
where salary = (select min(salary) from employees);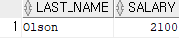

select max(sum(salary))
from employees
group by department_id;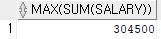
select department_name, sum(salary)
from employees
join departments using(department_id)
group by department_name
having sum(salary) = (select max(sum(salary))
from employees
group by department_id);

오스틴의 부서를 알아내고 오스틴의 급여를 알아내고 조인을 통해 알아야한다.
select department_id from employees where last_name='Austin';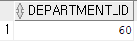
select salary from employees where last_name='Austin';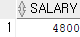
select last_name, department_name, salary
from employees
join departments using(department_id)
where department_id = (select department_id from employees where last_name='Austin')
and
salary = (select salary from employees where last_name='Austin');
2) 다중 행 서브쿼리(여러 행 반환) : in, any, all
Main Query
Sub Query -----> 여러 개의 결과
< any : 비교 대상 중 최대값보다 작음
> any : 비교 대상 중 최소값보다 큼 (ex. 과장직급의 급여를 받는 사원조회)
= any : in연산자와 동일
< all : 비교 대상 중 최솟값보다 작음
> all : 비교대상중 최대값보다 큼 (ex. 모든과장들의 직급보다 급여가 많은 사원조회)

'ST_MAN'의 직급의 급여가 얼마인지 봐야한다.
select salary from employees where job_id='ST_MAN'; --5800 ~ 8200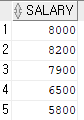
'IT_PROG'의 직급의 급여가 얼마인지 본다.
select salary from employees where job_id='IT_PROG'; --4200 ~ 9000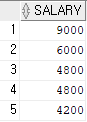
즉, 5800보다 큰 애들만 뽑아 오라는 것 → 6000 / 9000 이렇게만 있다.
select last_name, job_id, salary
from employees
where job_id = 'IT_PROG'
and
salary > any (select salary from employees where job_id='ST_MAN');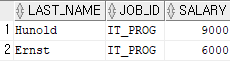

select max(salary) from employees where job_id='IT_PROG';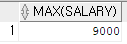
select salary from employees where job_id = 'FI_ACCOUNT';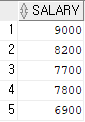
select salary from employees where job_id = 'SA_REP';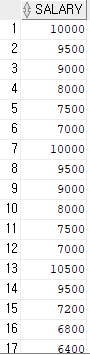
select last_name 사원명, job_id 업무ID, to_char(salary*1365, '99,999,999') || '원' 급여
from employees
where job_id in('FI_ACCOUNT', 'SA_REP')
and
salary > (select max(salary) from employees where job_id='IT_PROG')
order by salary desc;
all 붙인 것과 안 붙인 거의 차이점 알아보기
select last_name 사원명, job_id 업무ID, to_char(salary*1365, '99,999,999') || '원' 급여
from employees
where job_id in('FI_ACCOUNT', 'SA_REP')
and
salary > all (select max(salary) from employees where job_id='IT_PROG')
order by salary desc;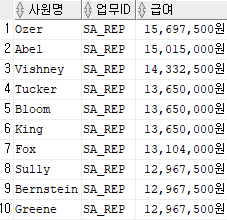
ALL과 ALL 없이 비교
- ALL 사용:
- ALL을 사용하면 서브쿼리에서 반환된 모든 값에 대해 비교를 수행합니다.
- 이 경우 서브쿼리가 하나의 값을 반환하기 때문에, 사실상 >와 같은 역할을 하게 됩니다.
- 즉, salary > max_salary와 동일하게 작동합니다.
- ALL을 사용하지 않는 경우:
- 단순히 salary > (select max(salary) ...)를 사용하면, salary가 서브쿼리의 반환 값보다 큰지를 확인합니다.
- 서브쿼리가 단일 값만 반환하기 때문에 ALL을 사용하지 않더라도 동일한 결과를 얻게 됩니다.

select salary from employees where job_id='IT_PROG' -- 4200, 4800, 6000, 9000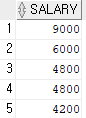
select last_name, job_id, salary
from employees
where salary=4200 or salary=4800 or salary=6000 or salary=9000;select last_name, job_id, salary
from employees
where salary in (4200, 4800, 6000, 9000);select last_name, job_id, salary
from employees
where salary in (select salary from employees where job_id='IT_PROG');
= any : in연산자와 동일
select last_name, job_id, salary
from employees
where salary =any (select salary from employees where job_id='IT_PROG');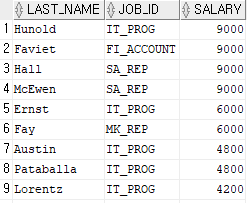

select manager_id from employees;
select distinct(manager_id) from employees;19명이 관리자인 것 확인할 수 있다.

select employee_id 사원번호, last_name 이름,
case
when employee_id in (select manager_id from employees) then '관리자'
else '직원'
end 구분
from employees
order by 3, 1;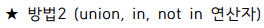
select employee_id 사원번호, last_name 이름, '관리자' 구분
from employees
where employee_id in (select manager_id from employees)
union
select employee_id 사원번호, last_name 이름, '직원' 구분
from employees
where employee_id not in (select manager_id from employees where manager_id is not null)
order by 3,13) 상관쿼리(correlated subquery)
: EXIST 연산자는 하위 쿼리에 레코드가 있는지 테스트하는 사용 된다
: EXIST 연산자는 하위 쿼리가 하나 이상의 레코드를 반환하면 true를 반환
: EXIST 연산자는 일반적으로 상관 관계가 있는 하위 쿼리와 함께 사용
: EXIST 연산자는 거의 * 로 구성된다
하위쿼리에 지정된 조건을 충족시키는 행이 있는지 없는지를 테스트하기 때문에 열 이름을 나열 할 의미가 없다

select employee_id 사원번호, last_name 이름, '관리자' 구분
from employees e
where exists (select null from employees where e.employee_id=manager_id)
union
select employee_id 사원번호, last_name 이름, '직원' 구분
from employees e
where not exists (select null from employees where e.employee_id=manager_id)
order by 3, 1;
- exists (select null from employees where e.employee_id=manager_id)에서 select null이 사용된 이유는 단순히 해당 서브쿼리가 결과를 반환할 수 있는지 여부만 확인하면 되기 때문입니다.
- 즉, 현재 직원(e.employee_id)이 다른 직원의 매니저로 등록되어 있다면, 해당 직원은 관리자임을 나타냅니다.
- not exists를 사용하여 다른 직원의 매니저가 아닌 경우를 찾습니다. 다시 말해, 서브쿼리의 결과가 없다면 해당 직원은 매니저가 아니라는 의미입니다.
결론
- exists나 not exists와 함께 서브쿼리에서 select null을 사용하는 이유는 단순히 서브쿼리의 결과 존재 여부만을 확인하고자 하기 때문입니다.
- 최종적으로 이 쿼리는 관리자와 일반 직원을 구분하여 정렬된 결과를 제공합니다.


1반 : 90
90
100
80
2반: 80
80
90
70
3반: 78
56
78
100
자기 반의 평균을 받고 있는 학생을 뽑아내는 것과 같다.
평균급여는 100단위 이하 절삭하는 방법
: trunc(avg(salary), -3)
select * from employees;
select job_id, trunc(avg(salary), -3) 평균급여
from employees
group by job_id;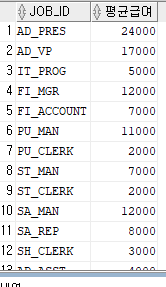
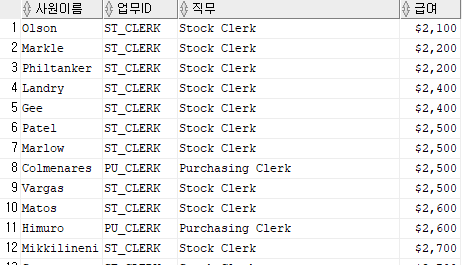
select last_name 사원이름, job_id 업무id, job_title 직무, to_char(salary, '$99,999') 급여
from employees
join jobs using(job_id)
where trunc(salary, -3) = (select job_id, trunc(avg(salary), -3)
from employees
group by job_id)
order by salary;
select last_name 사원이름, job_id 업무id, job_title 직무, to_char(salary, '$99,999') 급여
from employees
join jobs using(job_id)
where (job_id, trunc(salary, -3))
in (select job_id, trunc(avg(salary), -3)
from employees
group by job_id)
order by 4;
이렇게 두 개의 값을 다 비교해야할 때는 (A, B) in ( select ~~~ ) 이런식으로 해도된다는 것 !!
'Oracle' 카테고리의 다른 글
| DAY 31 - ORACLE DB - VIEW / 전체 복습 (2024.08.14) (0) | 2024.08.14 |
|---|---|
| DAY 30 - ORACLE 연습5 (2024.08.13) (0) | 2024.08.13 |
| DAY 28 - SELF JOIN / UNION / UNION ALL / INTERSECT / MINUS (2024.08.09) (0) | 2024.08.09 |
| DAY 15 - Oracle 설치(hr계정 / 사용자 계정_java) / 기본SQL / 트랜잭션 (2024.07.23) (0) | 2024.08.09 |
| DAY 15 - 기본 SQL HOMEWORK (2024.07.23) (0) | 2024.08.09 |
[하위질의 (SubQuery)] \
: 하나의 쿼리에 다른 쿼리가 포함되는 구조, ( )로처리
1) 단일 행 서브쿼리(단일 행 반환) : > , < , >=, <= , <> (!=)
Main Query
Sub Query -----> 1개결과
여기서 JOIN을 걸어야할지 Sub Query를 걸어야할지 고민해야한다.
부서코드를 알아낼 수 있는지 본다.
코드넘버가 90번이면 90번인 사람의 이름을 알 수 있게 되는 것이다.
select department_id from employees where first_name='Neena';select department_name from departments where department_id=90;
이렇게 따로 쓴 코드를 합쳐야한다.
select department_name
from departments
where department_id = (select department_id from employees where first_name='Neena');괄호 안에 있는 sql문 먼저 실행하여 부서코드를 알아내고
where문을 실행하여 그 부서코드에 있는 사람의 이름을 출력한다.
먼저 Neena라는 사원이있는 부서를 찾아야하고, 급여를 더 많이 받는 사원을 찾아야한다.
select department_id from employees where first_name = 'Neena';select salary from employees where first_name = 'Neena';select last_name, department_id, salary
from employees
where department_id = (select department_id from employees where first_name = 'Neena')
and salary > (select salary from employees where first_name = 'Neena');select min(salary) from employees;select last_name, salary
from employees
where salary = (select min(salary) from employees);
select max(sum(salary))
from employees
group by department_id;select department_name, sum(salary)
from employees
join departments using(department_id)
group by department_name
having sum(salary) = (select max(sum(salary))
from employees
group by department_id);
오스틴의 부서를 알아내고 오스틴의 급여를 알아내고 조인을 통해 알아야한다.
select department_id from employees where last_name='Austin';
select salary from employees where last_name='Austin';select last_name, department_name, salary
from employees
join departments using(department_id)
where department_id = (select department_id from employees where last_name='Austin')
and
salary = (select salary from employees where last_name='Austin');2) 다중 행 서브쿼리(여러 행 반환) : in, any, all
Main Query
Sub Query -----> 여러 개의 결과
< any : 비교 대상 중 최대값보다 작음
> any : 비교 대상 중 최소값보다 큼 (ex. 과장직급의 급여를 받는 사원조회)
= any : in연산자와 동일
< all : 비교 대상 중 최솟값보다 작음
> all : 비교대상중 최대값보다 큼 (ex. 모든과장들의 직급보다 급여가 많은 사원조회)
'ST_MAN'의 직급의 급여가 얼마인지 봐야한다.
select salary from employees where job_id='ST_MAN'; --5800 ~ 8200'IT_PROG'의 직급의 급여가 얼마인지 본다.
select salary from employees where job_id='IT_PROG'; --4200 ~ 9000
즉, 5800보다 큰 애들만 뽑아 오라는 것 → 6000 / 9000 이렇게만 있다.
select last_name, job_id, salary
from employees
where job_id = 'IT_PROG'
and
salary > any (select salary from employees where job_id='ST_MAN');select max(salary) from employees where job_id='IT_PROG';select salary from employees where job_id = 'FI_ACCOUNT';select salary from employees where job_id = 'SA_REP';select last_name 사원명, job_id 업무ID, to_char(salary*1365, '99,999,999') || '원' 급여
from employees
where job_id in('FI_ACCOUNT', 'SA_REP')
and
salary > (select max(salary) from employees where job_id='IT_PROG')
order by salary desc;
all 붙인 것과 안 붙인 거의 차이점 알아보기
select last_name 사원명, job_id 업무ID, to_char(salary*1365, '99,999,999') || '원' 급여
from employees
where job_id in('FI_ACCOUNT', 'SA_REP')
and
salary > all (select max(salary) from employees where job_id='IT_PROG')
order by salary desc;ALL과 ALL 없이 비교
- ALL 사용:
- ALL을 사용하면 서브쿼리에서 반환된 모든 값에 대해 비교를 수행합니다.
- 이 경우 서브쿼리가 하나의 값을 반환하기 때문에, 사실상 >와 같은 역할을 하게 됩니다.
- 즉, salary > max_salary와 동일하게 작동합니다.
- ALL을 사용하지 않는 경우:
- 단순히 salary > (select max(salary) ...)를 사용하면, salary가 서브쿼리의 반환 값보다 큰지를 확인합니다.
- 서브쿼리가 단일 값만 반환하기 때문에 ALL을 사용하지 않더라도 동일한 결과를 얻게 됩니다.
select salary from employees where job_id='IT_PROG' -- 4200, 4800, 6000, 9000select last_name, job_id, salary
from employees
where salary=4200 or salary=4800 or salary=6000 or salary=9000;select last_name, job_id, salary
from employees
where salary in (4200, 4800, 6000, 9000);select last_name, job_id, salary
from employees
where salary in (select salary from employees where job_id='IT_PROG');
= any : in연산자와 동일
select last_name, job_id, salary
from employees
where salary =any (select salary from employees where job_id='IT_PROG');select manager_id from employees;select distinct(manager_id) from employees;19명이 관리자인 것 확인할 수 있다.
select employee_id 사원번호, last_name 이름,
case
when employee_id in (select manager_id from employees) then '관리자'
else '직원'
end 구분
from employees
order by 3, 1;select employee_id 사원번호, last_name 이름, '관리자' 구분
from employees
where employee_id in (select manager_id from employees)
union
select employee_id 사원번호, last_name 이름, '직원' 구분
from employees
where employee_id not in (select manager_id from employees where manager_id is not null)
order by 3,13) 상관쿼리(correlated subquery)
: EXIST 연산자는 하위 쿼리에 레코드가 있는지 테스트하는 사용 된다
: EXIST 연산자는 하위 쿼리가 하나 이상의 레코드를 반환하면 true를 반환
: EXIST 연산자는 일반적으로 상관 관계가 있는 하위 쿼리와 함께 사용
: EXIST 연산자는 거의 * 로 구성된다
하위쿼리에 지정된 조건을 충족시키는 행이 있는지 없는지를 테스트하기 때문에 열 이름을 나열 할 의미가 없다
select employee_id 사원번호, last_name 이름, '관리자' 구분
from employees e
where exists (select null from employees where e.employee_id=manager_id)
union
select employee_id 사원번호, last_name 이름, '직원' 구분
from employees e
where not exists (select null from employees where e.employee_id=manager_id)
order by 3, 1;
- exists (select null from employees where e.employee_id=manager_id)에서 select null이 사용된 이유는 단순히 해당 서브쿼리가 결과를 반환할 수 있는지 여부만 확인하면 되기 때문입니다.
- 즉, 현재 직원(e.employee_id)이 다른 직원의 매니저로 등록되어 있다면, 해당 직원은 관리자임을 나타냅니다.
- not exists를 사용하여 다른 직원의 매니저가 아닌 경우를 찾습니다. 다시 말해, 서브쿼리의 결과가 없다면 해당 직원은 매니저가 아니라는 의미입니다.
결론
- exists나 not exists와 함께 서브쿼리에서 select null을 사용하는 이유는 단순히 서브쿼리의 결과 존재 여부만을 확인하고자 하기 때문입니다.
- 최종적으로 이 쿼리는 관리자와 일반 직원을 구분하여 정렬된 결과를 제공합니다.
1반 : 90
90
100
80
2반: 80
80
90
70
3반: 78
56
78
100
자기 반의 평균을 받고 있는 학생을 뽑아내는 것과 같다.
평균급여는 100단위 이하 절삭하는 방법
: trunc(avg(salary), -3)
select * from employees;
select job_id, trunc(avg(salary), -3) 평균급여
from employees
group by job_id;select last_name 사원이름, job_id 업무id, job_title 직무, to_char(salary, '$99,999') 급여
from employees
join jobs using(job_id)
where trunc(salary, -3) = (select job_id, trunc(avg(salary), -3)
from employees
group by job_id)
order by salary;select last_name 사원이름, job_id 업무id, job_title 직무, to_char(salary, '$99,999') 급여
from employees
join jobs using(job_id)
where (job_id, trunc(salary, -3))
in (select job_id, trunc(avg(salary), -3)
from employees
group by job_id)
order by 4;
이렇게 두 개의 값을 다 비교해야할 때는 (A, B) in ( select ~~~ ) 이런식으로 해도된다는 것 !!
'Oracle' 카테고리의 다른 글
| DAY 31 - ORACLE DB - VIEW / 전체 복습 (2024.08.14) (0) | 2024.08.14 |
|---|---|
| DAY 30 - ORACLE 연습5 (2024.08.13) (0) | 2024.08.13 |
| DAY 28 - SELF JOIN / UNION / UNION ALL / INTERSECT / MINUS (2024.08.09) (0) | 2024.08.09 |
| DAY 15 - Oracle 설치(hr계정 / 사용자 계정_java) / 기본SQL / 트랜잭션 (2024.07.23) (0) | 2024.08.09 |
| DAY 15 - 기본 SQL HOMEWORK (2024.07.23) (0) | 2024.08.09 |