


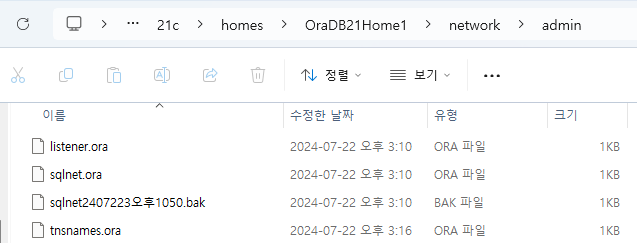
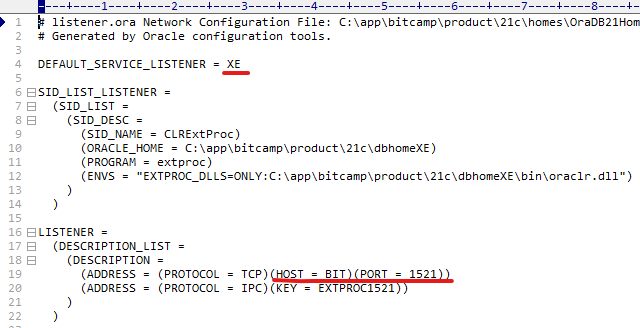
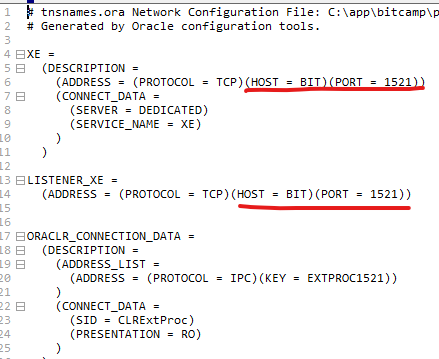
EditPlus로 연다.

select * from tab;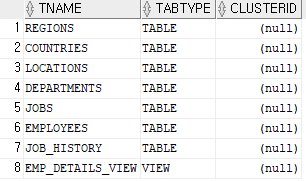
select * from user_sequences;
desc employees;

create user
table
sequence
drop user
table
sequence





select employee_id, last_name, salary from employees;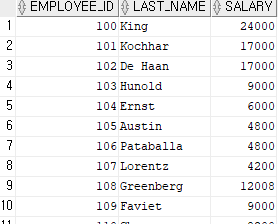

select employee_id as 사원번호, last_name as "이 름", salary as "급 여" from employees;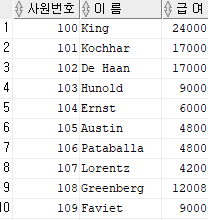

select employee_id as 사원번호, last_name as "이 름", salary*12 as "급 여" from employees;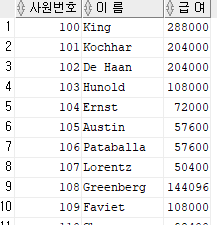

select first_name || ' ' || last_name as "이 름" from employees;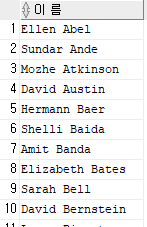

select employee_id as 사원번호,
first_name || ' ' || last_name as "이 름",
salary*12 || '달러' as "급 여" from employees;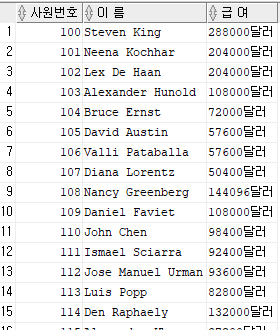
달러라는 단어 붙일 때도 똑같이 || 이거 이용하기

SELECT last_name || ' is a ' || job_id AS "Employee Detail"
FROM employees;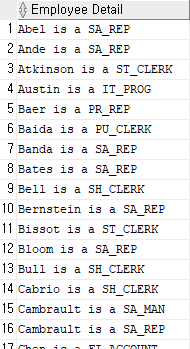

select distinct department_id from employees;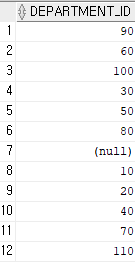

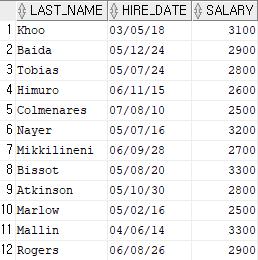
select last_name, hire_date, department_id
from employees
where department_id = 10 or department_id = 90;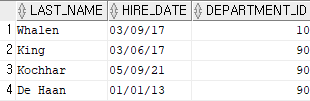

select last_name, hire_date, salary
from employees
where salary>=2500 and salary<3500;
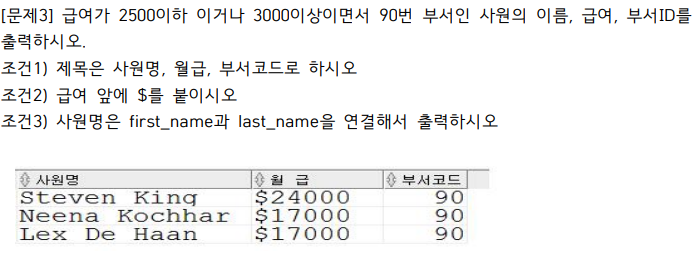
select first_name || ' ' || last_name 사원명, '$' || salary "월 급", department_id 부서코드
from employees
where (salary<=2500 or salary>=3000) and department_id = 90;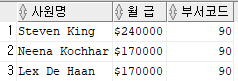

select * from employees where last_name='King';


select last_name, job_id, department_id
from employees
where job_id like '%MAN%';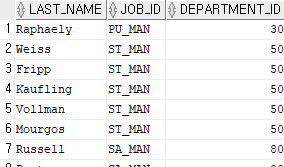
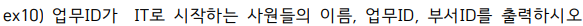
select last_name, job_id, department_id
from employees
where job_id like '%IT%';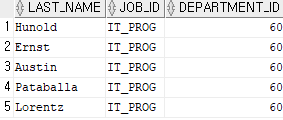

select last_name, salary, commission_pct
from employees
where commission_pct is not null;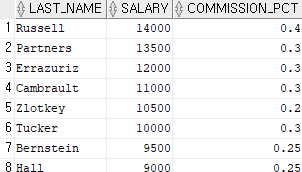

select last_name, salary, commission_pct
from employees
where commission_pct is null;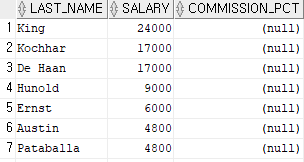

select employee_id, last_name, job_id
from employees
where job_id='FI_MGR' or job_id='FI_ACCOUNT';select employee_id, last_name, job_id
from employees
where job_id in('FI_MGR', 'FI_ACCOUNT');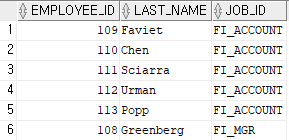

select employee_id, last_name, salary
from employees
where salary>=10000 and salary<=20000;select employee_id, last_name, salary
from employees
where salary between 10000 and 20000;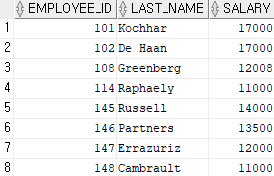
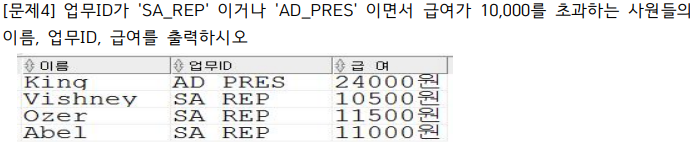
select last_name 이름, job_id 업무ID, salary || '원' "급 여"
from employees
where job_id in('SA_REP', 'AD_PRES') and salary > 10000;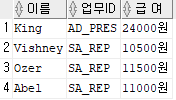

select distinct job_id from employees;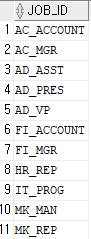

select employee_id 사원번호, last_name 이름, hire_date 입사일
from employees
where hire_date like '05%';
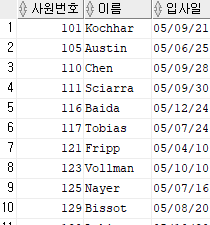
중간에 헷갈렸던 작은따옴표와 큰따옴표의 차이를 적어놨다.



select last_name, department_id, hire_date
from employees
order by 2 desc;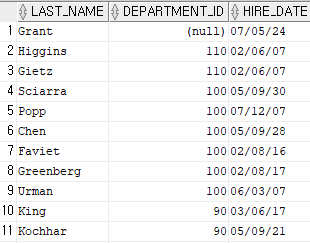

앞에 있는 데이터가 똑같아서 정렬이 안 될 때 뒤에 있는 것으로 정렬하겠다.
select last_name, department_id, hire_date
from employees
order by 2 desc, 3 asc;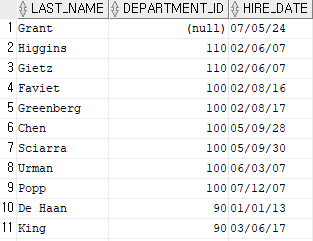
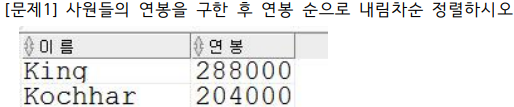
select last_name "이 름", salary*12 "연 봉"
from employees
order by 2 desc;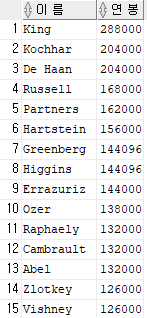
연봉 같은 애들은 이름으로 다시 오름차순하도록 !
select last_name "이 름", salary*12 "연 봉"
from employees
order by 2 desc, 1;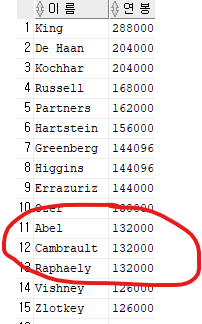

mod - 나머지 / round - 반올림 / trunc - 올림 / ceil - 내림
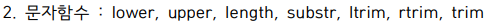
trim - 공백제거 / substr(문자열, 시작위치, 길이) - 문자열 자를 때

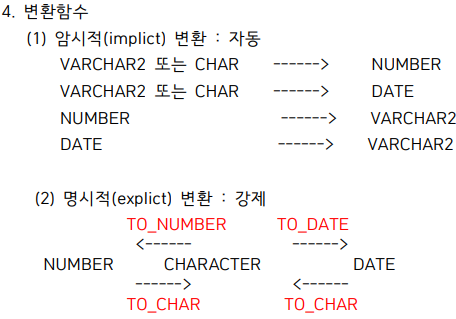
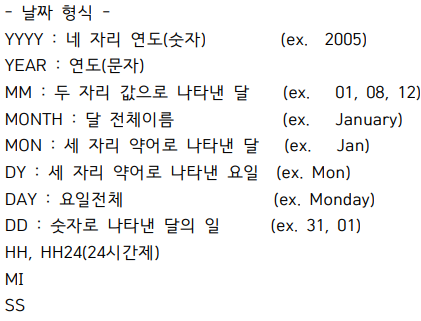

nvl - 값이 비어있으면 계산처리가 안되므로 nvl을 써줘야한다.
dcode - 다중if문, switch문

select employee_id, last_name, department_id
from employees
where lower(last_name)='higgins';
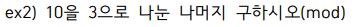
select mod(10, 3) from dual;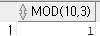

select round(35765.357, 2) from dual;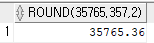
select round(35765.357, 0) from dual;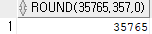
select round(35765.357, -3) from dual;
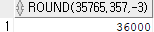
-3에서 반올림하게 되면, 반올림하고 뒤에는 다 잘려버림

select trunc(35765.357, 2) from dual;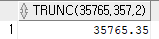
select trunc(35765.357, 0) from dual;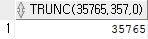
select trunc(35765.357, -3) from dual;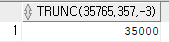
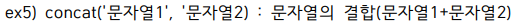
select concat('Hello', ' World') from dual;

create table text (
str1 char(20),
str2 varchar2(20));
insert into text(str1, str2) values('angel', 'angel');
insert into text(str1, str2) values('사천사', '사천사');
commit;select lengthb(str1), lengthb(str2) from text;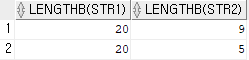
select length(str1), length(str2) from text;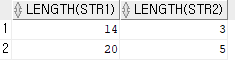
select length('korea') from dual; -- 5
select length('코리아') from dual; -- 3
select lengthb('korea') from dual; -- 5
select lengthb('코리아') from dual; -- 9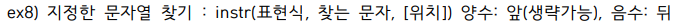
select instr('HelloWorld', 'W') from dual; -- 6
select instr('HelloWorld', 'o', -5) from dual; -- 5
select instr('HelloWorld', 'o', -1) from dual; -- 7
select substr('I am very happy', 6, 4) from dual; -- very
select substr('I am very happy', 6) from dual; -- very happy
select employee_id,
concat(first_name, last_name) name,
length(concat(first_name, last_name)) length
from employees
where substr(concat(first_name, last_name), -1) = 'n';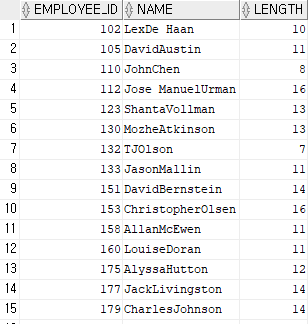
select employee_id,
concat(first_name, ' ' || last_name) name,
length(concat(first_name, ' ' || last_name)) length
from employees
where substr(last_name, -1) = 'n';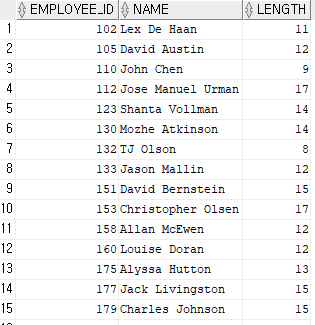
'Oracle' 카테고리의 다른 글
| DAY 15 - Oracle 설치(hr계정 / 사용자 계정_java) / 기본SQL / 트랜잭션 (2024.07.23) (0) | 2024.08.09 |
|---|---|
| DAY 15 - 기본 SQL HOMEWORK (2024.07.23) (0) | 2024.08.09 |
| DAY 27 - Oracle DB 연습3 - GROUP BY / JOIN (2024.08.08) (0) | 2024.08.08 |
| DAY 26 - Oracle DB 연습2 (2024.08.07) (1) | 2024.08.07 |
| DAY22 - JOIN (2024.08.06) (0) | 2024.08.06 |
EditPlus로 연다.
select * from tab;select * from user_sequences;desc employees;create user
table
sequence
drop user
table
sequenceselect employee_id, last_name, salary from employees;
select employee_id as 사원번호, last_name as "이 름", salary as "급 여" from employees;select employee_id as 사원번호, last_name as "이 름", salary*12 as "급 여" from employees;select first_name || ' ' || last_name as "이 름" from employees;select employee_id as 사원번호,
first_name || ' ' || last_name as "이 름",
salary*12 || '달러' as "급 여" from employees;
달러라는 단어 붙일 때도 똑같이 || 이거 이용하기
SELECT last_name || ' is a ' || job_id AS "Employee Detail"
FROM employees;select distinct department_id from employees;
select last_name, hire_date, department_id
from employees
where department_id = 10 or department_id = 90;select last_name, hire_date, salary
from employees
where salary>=2500 and salary<3500;
select first_name || ' ' || last_name 사원명, '$' || salary "월 급", department_id 부서코드
from employees
where (salary<=2500 or salary>=3000) and department_id = 90;
select * from employees where last_name='King';select last_name, job_id, department_id
from employees
where job_id like '%MAN%';select last_name, job_id, department_id
from employees
where job_id like '%IT%';
select last_name, salary, commission_pct
from employees
where commission_pct is not null;select last_name, salary, commission_pct
from employees
where commission_pct is null;select employee_id, last_name, job_id
from employees
where job_id='FI_MGR' or job_id='FI_ACCOUNT';select employee_id, last_name, job_id
from employees
where job_id in('FI_MGR', 'FI_ACCOUNT');select employee_id, last_name, salary
from employees
where salary>=10000 and salary<=20000;select employee_id, last_name, salary
from employees
where salary between 10000 and 20000;select last_name 이름, job_id 업무ID, salary || '원' "급 여"
from employees
where job_id in('SA_REP', 'AD_PRES') and salary > 10000;
select distinct job_id from employees;
select employee_id 사원번호, last_name 이름, hire_date 입사일
from employees
where hire_date like '05%';
중간에 헷갈렸던 작은따옴표와 큰따옴표의 차이를 적어놨다.
select last_name, department_id, hire_date
from employees
order by 2 desc;앞에 있는 데이터가 똑같아서 정렬이 안 될 때 뒤에 있는 것으로 정렬하겠다.
select last_name, department_id, hire_date
from employees
order by 2 desc, 3 asc;select last_name "이 름", salary*12 "연 봉"
from employees
order by 2 desc;
연봉 같은 애들은 이름으로 다시 오름차순하도록 !
select last_name "이 름", salary*12 "연 봉"
from employees
order by 2 desc, 1;mod - 나머지 / round - 반올림 / trunc - 올림 / ceil - 내림
trim - 공백제거 / substr(문자열, 시작위치, 길이) - 문자열 자를 때
nvl - 값이 비어있으면 계산처리가 안되므로 nvl을 써줘야한다.
dcode - 다중if문, switch문
select employee_id, last_name, department_id
from employees
where lower(last_name)='higgins';
select mod(10, 3) from dual;
select round(35765.357, 2) from dual;
select round(35765.357, 0) from dual;
select round(35765.357, -3) from dual;
-3에서 반올림하게 되면, 반올림하고 뒤에는 다 잘려버림
select trunc(35765.357, 2) from dual;
select trunc(35765.357, 0) from dual;
select trunc(35765.357, -3) from dual;
select concat('Hello', ' World') from dual;create table text (
str1 char(20),
str2 varchar2(20));insert into text(str1, str2) values('angel', 'angel');
insert into text(str1, str2) values('사천사', '사천사');
commit;select lengthb(str1), lengthb(str2) from text;
select length(str1), length(str2) from text;select length('korea') from dual; -- 5
select length('코리아') from dual; -- 3
select lengthb('korea') from dual; -- 5
select lengthb('코리아') from dual; -- 9select instr('HelloWorld', 'W') from dual; -- 6
select instr('HelloWorld', 'o', -5) from dual; -- 5
select instr('HelloWorld', 'o', -1) from dual; -- 7select substr('I am very happy', 6, 4) from dual; -- very
select substr('I am very happy', 6) from dual; -- very happyselect employee_id,
concat(first_name, last_name) name,
length(concat(first_name, last_name)) length
from employees
where substr(concat(first_name, last_name), -1) = 'n';
select employee_id,
concat(first_name, ' ' || last_name) name,
length(concat(first_name, ' ' || last_name)) length
from employees
where substr(last_name, -1) = 'n';'Oracle' 카테고리의 다른 글
| DAY 15 - Oracle 설치(hr계정 / 사용자 계정_java) / 기본SQL / 트랜잭션 (2024.07.23) (0) | 2024.08.09 |
|---|---|
| DAY 15 - 기본 SQL HOMEWORK (2024.07.23) (0) | 2024.08.09 |
| DAY 27 - Oracle DB 연습3 - GROUP BY / JOIN (2024.08.08) (0) | 2024.08.08 |
| DAY 26 - Oracle DB 연습2 (2024.08.07) (1) | 2024.08.07 |
| DAY22 - JOIN (2024.08.06) (0) | 2024.08.06 |