
0 ~ 9
10 ~ 19
20 ~ 29
30 ~ 39
40 ~ 49
50 ~ 59
60 ~ 69
70 ~ 79
80 ~ 89
90 ~ 99
100
select width_bucket(74, 0, 100, 10) from dual; -- 8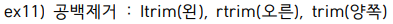
select rtrim('test ') || 'exam' from dual;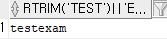
- TO_CHAR(날짜타입값, '날짜포맷')
날짜타입의 데이터를 '날짜포맷'에 따라 문자열로 변환
- TO_DATE('날짜문자열', '날짜포맷')
'날짜포맷'에 맞춘 날짜문자열을 날짜타입값으로 변환


select sysdate from dual;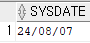
- 바깥이 싱글 따옴표이면 안에는 더블따옴표를 써야한다.
select to_char(sysdate, 'YYYY"년" MM"월" DD"일"') as 오늘날짜 from dual;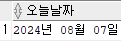
select to_char(sysdate, 'HH"시" MI"분" SS"초"') as 오늘날짜 from dual;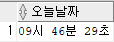
select to_char(sysdate, 'HH24"시" MI"분" SS"초"') as 오늘날짜 from dual;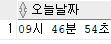

select add_months(sysdate, 7) from dual;

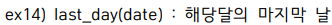
select last_day(sysdate) from dual;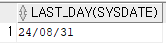
select last_day('2004-02-01') from dual; -- 29
select last_day('2005-02-01') from dual; -- 28
select last_day(sysdate) - sysdate from dual;
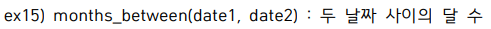
select round(months_between('95-10-21', '94-10-20'), 0) from dual; -- 자동 형변환
날짜 계산은 무조건 초단위로 한다. 그러므로 round 이용해서 반올림해줌.

select last_name, to_char(salary, 'L99,999.00')
from employees
where last_name='King';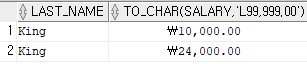
L99,999.00
통화기호/ 3자리마다 쉼표 / 소수점 2째자리까지
select to_char(to_date('97/9/30', 'YY-MM-DD') , 'YYYY-MON-DD') from dual; -- 2097
select to_char(to_date('97/9/30', 'RR-MM-DD') , 'RRRR-MON-DD') from dual; -- 1997
select to_char(to_date('17/9/30', 'YY-MM-DD') , 'YYYY-MON-DD') from dual; -- 2017
select to_char(to_date('17/9/30', 'RR-MM-DD') , 'RRRR-MON-DD') from dual; -- 2017
년도의 앞의 2자리는 시스템의 날짜로부터 가져온다.( yyyy)

97
1997
2097
1997 2024 2097
27 73
가까운데로 가는 것 → 1997
17
1917
2017
1917 2024 2017 → 2017
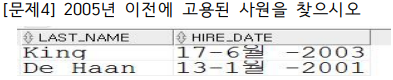
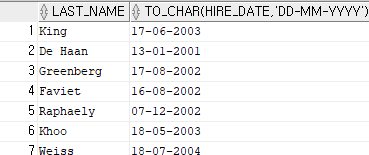
select last_name, to_char(hire_date, 'DD-MM-YYYY')
from employees
where hire_date < to_date('05/01/01', 'YY-MM-DD');
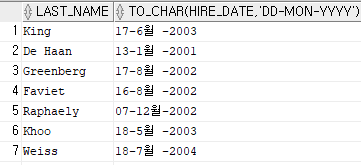
select last_name, to_char(hire_date, 'DD-Mon-YYYY')
from employees
where hire_date < '2005/01/01';
※ 굳이 to_char 할 필요없다. 알아서 형변환을 해준다는 것...!!
- TO_CHAR(날짜타입값, '날짜포맷')
날짜타입의 데이터를 '날짜포맷'에 따라 문자열로 변환
- TO_DATE('날짜문자열', '날짜포맷')
'날짜포맷'에 맞춘 날짜문자열을 날짜타입값으로 변환

select last_name, hire_date from employees where hire_date='05/09/30'; --05/09/30
select last_name, hire_date from employees where hire_date='05/9/30'; --05/09/30select to_char(sysdate, 'YYYY-MM-DD') from dual; --2024-08-07
select to_char(sysdate, 'YYYY-fmMM-DD') from dual; --2024-8-7select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-MM-DD') from dual; -- 2011-03-01
select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-fmMM-DD') from dual; -- 2011-3-1
select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-fmMM-fmDD') from dual;-- 2011-3-01
select max(salary),
min(salary),
trunc(avg(salary), 0),
to_char(sum(salary), 'L9,999,999') from employees;

방법 2가지 있다 !!
select count(nvl(commission_pct, 0))
from employees
where commission_id is null;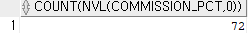
select count(*)
from employees
where commission_pct is null;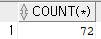
count는 값이 비어있으면 빼고 나옴.
count(*) 이렇게 하면 모든 항목 개수 나옴.

select department_id from employees; -- 107
select count(department_id) from employees; -- 106
select count(*) from employees; -- 107
select count(distinct department_id) from employees; -- 11
select count(distinct nvl(department_id, 0)) from employees; -- 12
select distinct nvl(department_id, 0) from employees; -- nvl은 null값을 0으로 대치
if(a==1) A;
else if(a==2) B;
else if(a==3) C;
else D;
----------------------
switch(a){
case 1: A;
case 2: B;
case 3: C;
default D;
}
decode(a, 1, A, 2, B, 3, C, D) - 이렇게 쓰면 보기 힘들다.
decode(a,
1, A,
2, B,
3, C,
D)
--------------------------------------------
case
when a=1 then A;
when a=2 then B;
when a=3 then C;
else D;
end
case a
when 1 then A;
when 2 then B;
when 3 then C;
else D;
end

select job_id, decode(job_id,
'SA_MAN', 'Sales Dept',
'SA_REP', 'Sales Dept',
'Another') "분류"
from employees
order by 2;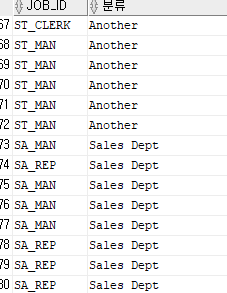
select job_id, case job_id
when 'SA_MAN' then 'Sales Dept'
when 'SA_REP' then 'Sales Dept'
else 'Another'
end "분류"
from employees
order by 2;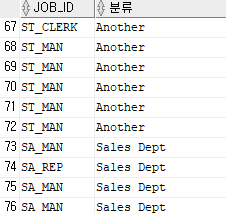
select job_id, case
when job_id='SA_MAN' then 'Sales Dept'
when job_id='SA_REP' then 'Sales Dept'
else 'Another'
end "분류"
from employees
order by 2;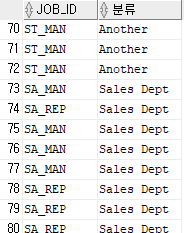

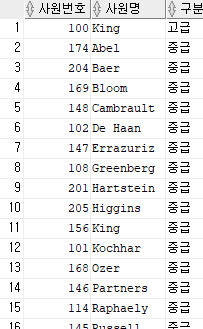
select employee_id 사원번호,
last_name 사원명,
case
when salary < 10000 then '초급'
when salary < 20000 then '중급'
else '고급'
end "구분"
from employees
order by 3, 2;
오름차순(asc) 생략 가능 !!
칼럼명 안 넣고 칼럼 순서로 적어도 된다 !
then 뒤에는 싱글따옴표 꼭 써서 들어가야 한다 !! (데이터로 들어가는 것이므로)

select rank(3000) within group(order by salary desc) "rank" from employees;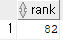

select employee_id, salary, rank() over(order by salary desc) "rank" from employees;
- within은 원하는 값만
- over는 전부 출력

select employee_id,
salary,
department_id,
first_value(salary) over(partition by department_id order by salary desc)
"highsal_deptID"
from employees;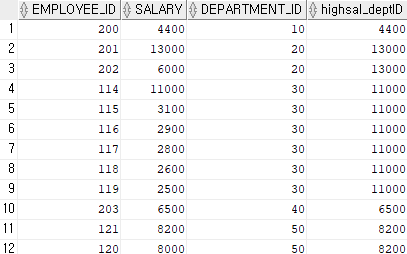

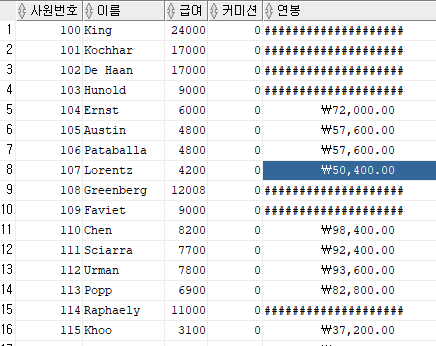
select employee_id 사원번호,
last_name 이름,
salary 급여,
nvl(commission_pct, 0) 커미션,
to_char((salary * 12 + (salary * 12 * nvl(commission_pct, 0))), 'L99,999.00') 연봉
from employees;
커미션이 값이 null이면 계산에 문제가 생긴다.
그러므로 nvl을 이용해줘야 한다.
select employee_id 사원번호,
last_name 이름,
salary 급여,
nvl(commission_pct, 0) 커미션,
to_char(salary * 12 + (salary * 12 * nvl(commission_pct, 0)), '$9,999,999') 연봉
from employees;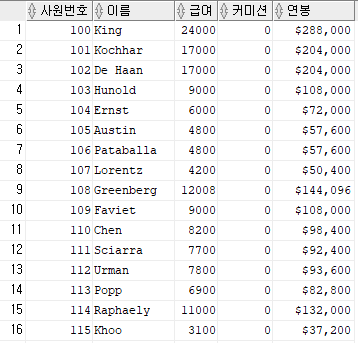

select employee_id 사원번호,
last_name 이름,
nvl(manager_id, 1000) 매니저ID
from employees;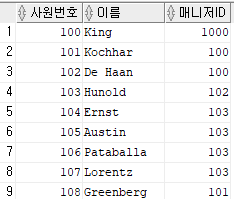
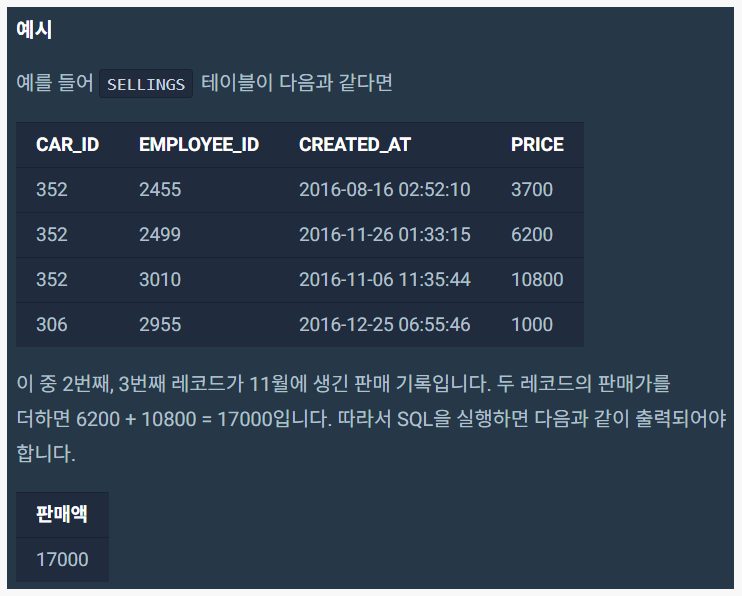
select sum(price)
from sellings
where created_at like '%2016-11%';1. 유공과와 생물과, 식영과 학생을 검색하고 오름차순으로 정렬하시오
테이블 : STUDENT
select * from student
where major in('유공', '생물', '식영')
order by major;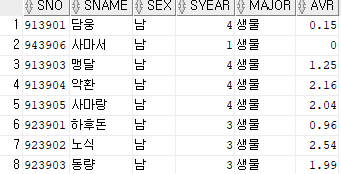
2. 평점이 2.0에서 3.0사이인 학생을 검색하시오 (BETWEEN ~ AND 사용)
테이블 : STUDENT
select * from student
where avr between 2.0 and 3.0;
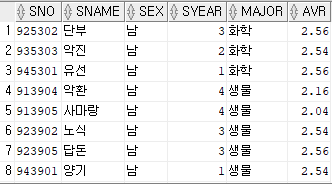
3. 성과 이름이 각각 1글자인 교수를 검색하라
테이블 : PROFESSOR
select * from professor
where pname like '__';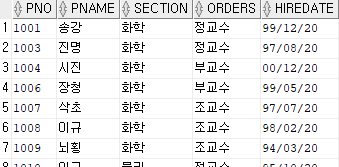
'Oracle' 카테고리의 다른 글
| DAY 15 - Oracle 설치(hr계정 / 사용자 계정_java) / 기본SQL / 트랜잭션 (2024.07.23) (0) | 2024.08.09 |
|---|---|
| DAY 15 - 기본 SQL HOMEWORK (2024.07.23) (0) | 2024.08.09 |
| DAY 27 - Oracle DB 연습3 - GROUP BY / JOIN (2024.08.08) (0) | 2024.08.08 |
| DAY22 - JOIN (2024.08.06) (0) | 2024.08.06 |
| DAY25 - Oracle DB 연습 (2024.08.06) (0) | 2024.08.06 |
0 ~ 9
10 ~ 19
20 ~ 29
30 ~ 39
40 ~ 49
50 ~ 59
60 ~ 69
70 ~ 79
80 ~ 89
90 ~ 99
100
select width_bucket(74, 0, 100, 10) from dual; -- 8select rtrim('test ') || 'exam' from dual;- TO_CHAR(날짜타입값, '날짜포맷')
날짜타입의 데이터를 '날짜포맷'에 따라 문자열로 변환
- TO_DATE('날짜문자열', '날짜포맷')
'날짜포맷'에 맞춘 날짜문자열을 날짜타입값으로 변환
select sysdate from dual;
- 바깥이 싱글 따옴표이면 안에는 더블따옴표를 써야한다.
select to_char(sysdate, 'YYYY"년" MM"월" DD"일"') as 오늘날짜 from dual;select to_char(sysdate, 'HH"시" MI"분" SS"초"') as 오늘날짜 from dual;select to_char(sysdate, 'HH24"시" MI"분" SS"초"') as 오늘날짜 from dual;select add_months(sysdate, 7) from dual;
select last_day(sysdate) from dual;select last_day('2004-02-01') from dual; -- 29
select last_day('2005-02-01') from dual; -- 28select last_day(sysdate) - sysdate from dual;select round(months_between('95-10-21', '94-10-20'), 0) from dual; -- 자동 형변환날짜 계산은 무조건 초단위로 한다. 그러므로 round 이용해서 반올림해줌.
select last_name, to_char(salary, 'L99,999.00')
from employees
where last_name='King';
L99,999.00
통화기호/ 3자리마다 쉼표 / 소수점 2째자리까지
select to_char(to_date('97/9/30', 'YY-MM-DD') , 'YYYY-MON-DD') from dual; -- 2097
select to_char(to_date('97/9/30', 'RR-MM-DD') , 'RRRR-MON-DD') from dual; -- 1997
select to_char(to_date('17/9/30', 'YY-MM-DD') , 'YYYY-MON-DD') from dual; -- 2017
select to_char(to_date('17/9/30', 'RR-MM-DD') , 'RRRR-MON-DD') from dual; -- 2017
년도의 앞의 2자리는 시스템의 날짜로부터 가져온다.( yyyy)
97
1997
2097
1997 2024 2097
27 73
가까운데로 가는 것 → 1997
17
1917
2017
1917 2024 2017 → 2017
select last_name, to_char(hire_date, 'DD-MM-YYYY')
from employees
where hire_date < to_date('05/01/01', 'YY-MM-DD');
select last_name, to_char(hire_date, 'DD-Mon-YYYY')
from employees
where hire_date < '2005/01/01';
※ 굳이 to_char 할 필요없다. 알아서 형변환을 해준다는 것...!!
- TO_CHAR(날짜타입값, '날짜포맷')
날짜타입의 데이터를 '날짜포맷'에 따라 문자열로 변환
- TO_DATE('날짜문자열', '날짜포맷')
'날짜포맷'에 맞춘 날짜문자열을 날짜타입값으로 변환
select last_name, hire_date from employees where hire_date='05/09/30'; --05/09/30
select last_name, hire_date from employees where hire_date='05/9/30'; --05/09/30select to_char(sysdate, 'YYYY-MM-DD') from dual; --2024-08-07
select to_char(sysdate, 'YYYY-fmMM-DD') from dual; --2024-8-7select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-MM-DD') from dual; -- 2011-03-01
select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-fmMM-DD') from dual; -- 2011-3-1
select to_char(to_date('2011-03-01','YYYY-MM-DD'), 'YYYY-fmMM-fmDD') from dual;-- 2011-3-01select max(salary),
min(salary),
trunc(avg(salary), 0),
to_char(sum(salary), 'L9,999,999') from employees;
방법 2가지 있다 !!
select count(nvl(commission_pct, 0))
from employees
where commission_id is null;select count(*)
from employees
where commission_pct is null;count는 값이 비어있으면 빼고 나옴.
count(*) 이렇게 하면 모든 항목 개수 나옴.
select department_id from employees; -- 107
select count(department_id) from employees; -- 106
select count(*) from employees; -- 107
select count(distinct department_id) from employees; -- 11
select count(distinct nvl(department_id, 0)) from employees; -- 12
select distinct nvl(department_id, 0) from employees; -- nvl은 null값을 0으로 대치if(a==1) A;
else if(a==2) B;
else if(a==3) C;
else D;
----------------------
switch(a){
case 1: A;
case 2: B;
case 3: C;
default D;
}
decode(a, 1, A, 2, B, 3, C, D) - 이렇게 쓰면 보기 힘들다.
decode(a,
1, A,
2, B,
3, C,
D)
--------------------------------------------
case
when a=1 then A;
when a=2 then B;
when a=3 then C;
else D;
end
case a
when 1 then A;
when 2 then B;
when 3 then C;
else D;
end
select job_id, decode(job_id,
'SA_MAN', 'Sales Dept',
'SA_REP', 'Sales Dept',
'Another') "분류"
from employees
order by 2;select job_id, case job_id
when 'SA_MAN' then 'Sales Dept'
when 'SA_REP' then 'Sales Dept'
else 'Another'
end "분류"
from employees
order by 2;select job_id, case
when job_id='SA_MAN' then 'Sales Dept'
when job_id='SA_REP' then 'Sales Dept'
else 'Another'
end "분류"
from employees
order by 2;
select employee_id 사원번호,
last_name 사원명,
case
when salary < 10000 then '초급'
when salary < 20000 then '중급'
else '고급'
end "구분"
from employees
order by 3, 2;
오름차순(asc) 생략 가능 !!
칼럼명 안 넣고 칼럼 순서로 적어도 된다 !
then 뒤에는 싱글따옴표 꼭 써서 들어가야 한다 !! (데이터로 들어가는 것이므로)
select rank(3000) within group(order by salary desc) "rank" from employees;select employee_id, salary, rank() over(order by salary desc) "rank" from employees;
- within은 원하는 값만
- over는 전부 출력
select employee_id,
salary,
department_id,
first_value(salary) over(partition by department_id order by salary desc)
"highsal_deptID"
from employees;select employee_id 사원번호,
last_name 이름,
salary 급여,
nvl(commission_pct, 0) 커미션,
to_char((salary * 12 + (salary * 12 * nvl(commission_pct, 0))), 'L99,999.00') 연봉
from employees;
커미션이 값이 null이면 계산에 문제가 생긴다.
그러므로 nvl을 이용해줘야 한다.
select employee_id 사원번호,
last_name 이름,
salary 급여,
nvl(commission_pct, 0) 커미션,
to_char(salary * 12 + (salary * 12 * nvl(commission_pct, 0)), '$9,999,999') 연봉
from employees;select employee_id 사원번호,
last_name 이름,
nvl(manager_id, 1000) 매니저ID
from employees;select sum(price)
from sellings
where created_at like '%2016-11%';1. 유공과와 생물과, 식영과 학생을 검색하고 오름차순으로 정렬하시오
테이블 : STUDENT
select * from student
where major in('유공', '생물', '식영')
order by major;
2. 평점이 2.0에서 3.0사이인 학생을 검색하시오 (BETWEEN ~ AND 사용)
테이블 : STUDENT
select * from student
where avr between 2.0 and 3.0;
3. 성과 이름이 각각 1글자인 교수를 검색하라
테이블 : PROFESSOR
select * from professor
where pname like '__';'Oracle' 카테고리의 다른 글
| DAY 15 - Oracle 설치(hr계정 / 사용자 계정_java) / 기본SQL / 트랜잭션 (2024.07.23) (0) | 2024.08.09 |
|---|---|
| DAY 15 - 기본 SQL HOMEWORK (2024.07.23) (0) | 2024.08.09 |
| DAY 27 - Oracle DB 연습3 - GROUP BY / JOIN (2024.08.08) (0) | 2024.08.08 |
| DAY22 - JOIN (2024.08.06) (0) | 2024.08.06 |
| DAY25 - Oracle DB 연습 (2024.08.06) (0) | 2024.08.06 |